Armazenamento
Armazenamento Local
Assim como discutido em DTN (Data Transfer Node), um dos pontos-chave é o uso de uma arquitetura de armazenamento inteiramente dedicada a leitura e escrita em alto desempenho por longo tempo.
Um exemplo típico de DTN, encontrado em testbeds avançados como os da RNP, possui discos NVMe (Non-Volatile Memory Express) configurados em RAID 0, permitindo atingir taxas superiores a 100 Gbps. Em arquiteturas duo-processadas, que utilizam dois processadores organizados em NUMAs, é crucial que os componentes principais, como discos e NICs (Network Interface Cards), sejam vinculados à mesma CPU. Essa prática reduz a dependência do barramento entre os Numas, isto é, entre os CPUs, evitando atrasos adicionais que prejudicam o desempenho. Além disso, os processos responsáveis pela movimentação de dados são propositalmente alocados para operar na mesma CPU que os discos e a NIC, assim garantindo menor latência e maior eficiência.
Dispositivos de armazenamento
Nova arquitetura de discos baseados em NVMe (Non-Volatile Memory Express)
- Disco de estado sólido sobre PCI Express (x4)
- interfaces PCIe, M.2, U.2 ou U.3, por exemplo.
- Menor latência e maior paralelismo no acesso aos dados

Servidores Especializados

Exemplo de Especificação para 100G+

Contudo, embora ideal e mais simples, a arquitetura de armazenamento interno nem sempre é possível em todos contextos e ambientes. Pode vir a ser necessário a separação de um ambiente exclusivamente de armazenamento e o do DTN propriamente dito. Nesse sentido, há estudos dedicados a exploração de protocolos de acesso a dados remotos como o NFS (Network File System), o qual pode ser visto a seguir.
NFS
O NFS (Network File System) é um protocolo de sistema de arquivos distribuído que permite a manipulação de diretórios e arquivos armazenados em um servidor remoto como se fossem locais. Amplamente utilizado e comum em diversos sistemas operacionais, estes enxergam o diretório normalmente como qualquer outro filesystem, permitindo então que as aplicações acessem arquivos remotos sem necessidade de adaptação, utilizando as mesmas chamadas de sistema que usariam para arquivos locais.
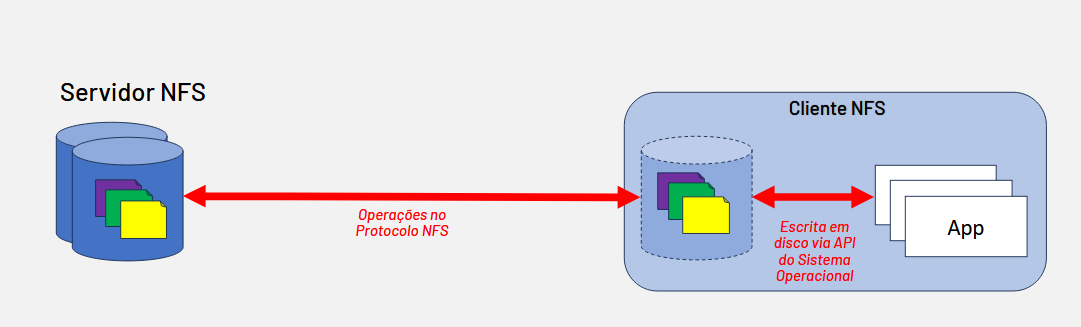
Diferente do Armazenamento Local, ao invés de haver discos NVMEs no próprio DTN, a abordagem do NFS permite que seja usado discos em máquina externa ou mesmo o uso de storages mais especializados. No contexto de e-Ciência, devido a ampla variedade de arquitetura, hardwares e infraestrutura de instituições e laboratórios, seu modelo cliente-servidor o torna uma alternativa versátil, capaz de se adequar a múltiplos cenários e proporcionar isolamento entre o storage de propósito geral e o DTN.
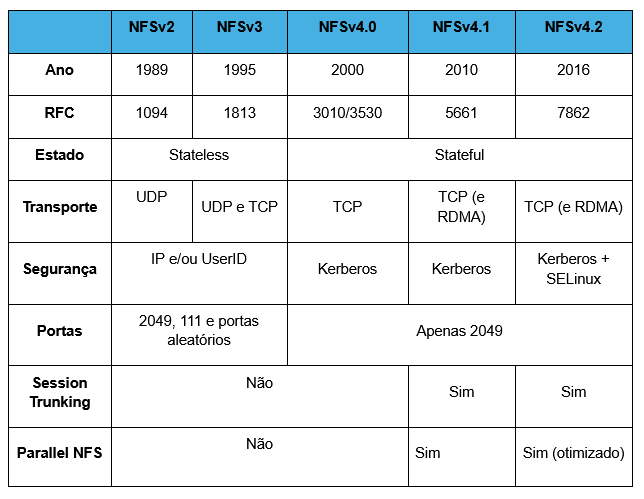
Contudo, durante muito tempo o NFS foi sempre muito recomendado e utilizado em cenários que não demandavam alto desempenho, isto é, cópias simples e compartilhamento de dados entre estações de trabalho, por exemplo. Com o NFSv4.1 (que introduziu o pNFS) e, principalmente, o NFSv4.2, abriu-se possibilidade de explorar cenários com exigência com grandes volumes de dados e workloads mais pesados.
Session Trunking e nConnect
O cliente NFS tradicional abre apenas uma conexão TCP com o servidor NFS, o que pode gerar um gargalo de processamento no servidor em redes 100+ Gbps que utilizam do mecanismo RSS (Receive Side Scaling): todo o processamento é distribuído para o core com um único fluxo de duração, sobrecarregando-o.
O Session Trunking foi introduzido na versão 4.1 do NFS e possibilita agregar fluxos provenientes de diferentes interfaces de rede em uma mesma sessão. Dessa forma, o servidor distribui os fluxos entre diferentes cores, agregando-se desempenho ao ambiente.
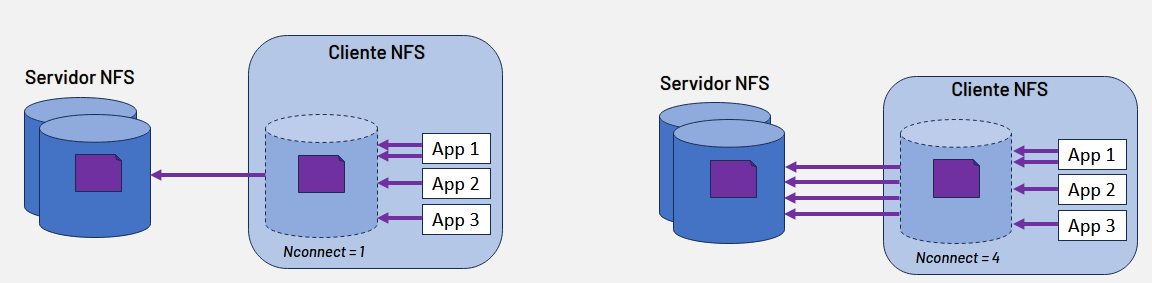
Introduzido na versão 4.2 do NFS, o parâmetro nConnect aproveitou o Session Trunking e é uma funcionalidade exclusiva do Linux que permite o estabelecimento de até 16 conexões TCP paralelas. Ao viabilizar múltiplos fluxos simultâneos, o recurso promove o balanceamento da carga de CPU, mostrando-se altamente eficaz em cenários com diversas aplicações concorrentes ou operações que exigem alto grau de paralelismo.
Parallel NFS (pNFS)
Com o pNFS, é possível criar um cluster de servidores NFS, que trabalham em paralelo:
-
Em uma leitura, um cliente acessa um servidor de metadados (o MDS – MetaData Server), que aponta para a localização dos blocos de dados desejados em outros servidores do cluster (os chamados DS – Data Servers);
-
A partir daí o cliente abre conexões diretas e paralelas aos diferentes DS, trazendo os dados de forma paralela
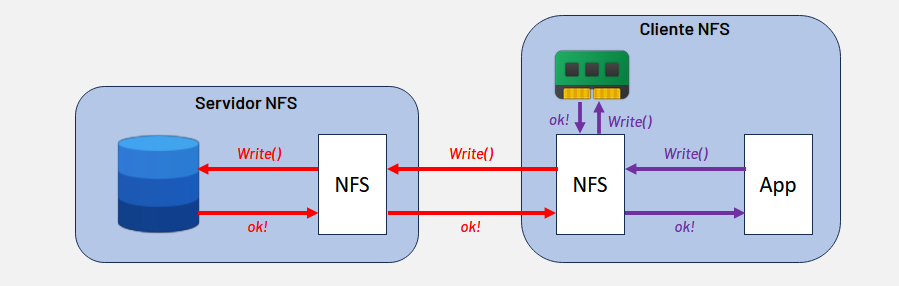
Escrita Async e Sync no Cliente
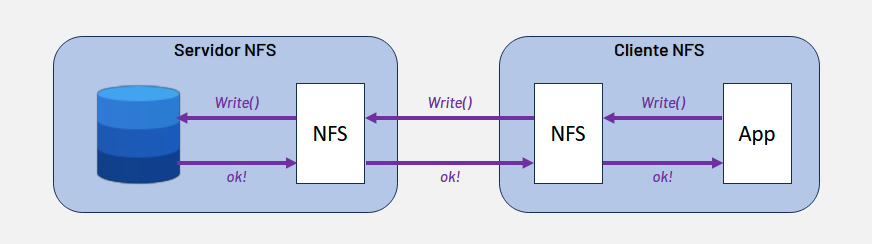
Complementando essa eficiência na conectividade, o desempenho no lado do cliente também depende criticamente do modo de escrita adotado: Sync ou Async. No modo Sync, os dados são enviados diretamente ao servidor e a aplicação só é notificada após a gravação física no disco, o que pode se tornar um gargalo em ambientes de alta performance. Já o modo Async, default do client NFS, contorna essa limitação ao utilizar um buffer de memória controlado pelo kernel Linux; nele, a aplicação prossegue com suas tarefas assim que os dados atingem a memória, enquanto a persistência final no servidor ocorre de maneira otimizada e em segundo plano.
Threads no Servidor
O número de threads no servidor NFS define quantas requisições de clientes o servidor consegue processar em paralelo. O recomendado para otimizar desempenho do lado do servidor é aumentar o número de threads proporcionalmente aos valores configurados no parâmetro nConnect e ao número de clientes da operação. O valor máximo no Linux é de 32 threads.